Reza Jahadi
Software Engineer and AI researcher
Software Engineer and AI researcher
Hello! I'm Reza, an AI engineer and embedded systems developer with a deep passion for building efficient machine learning systems from the ground up. My work bridges the gap between high-level model optimization, such as pruning, quantization, and transformer compression and low-level system design on real-world hardware.
I thrive at the intersection of software and hardware, where performance, scalability, and resource constraints drive innovation. Whether optimizing deep learning models for deployment or developing firmware and drivers on embedded platforms, I bring a systems-level mindset and hands-on experience that spans the entire ML stack.
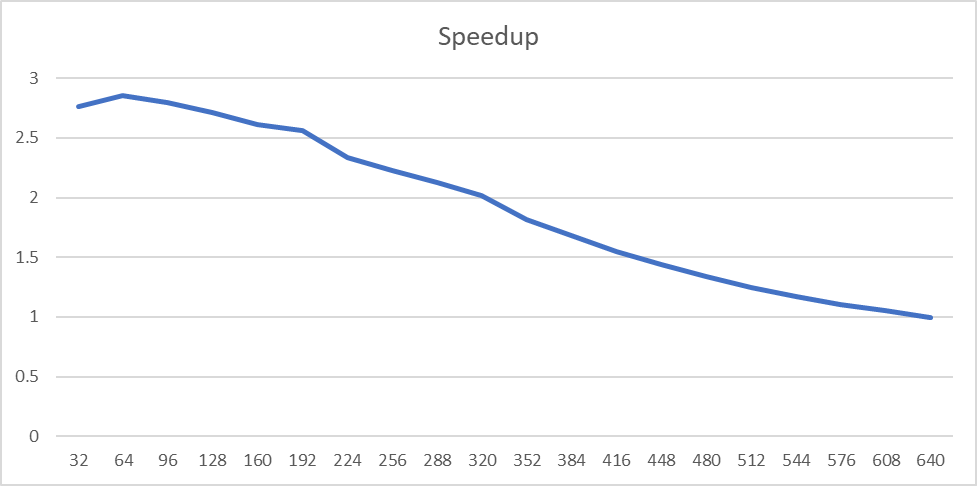
Performing matrix-vector multiplication using row-wise decomposition on GPU and measuring the speedup.
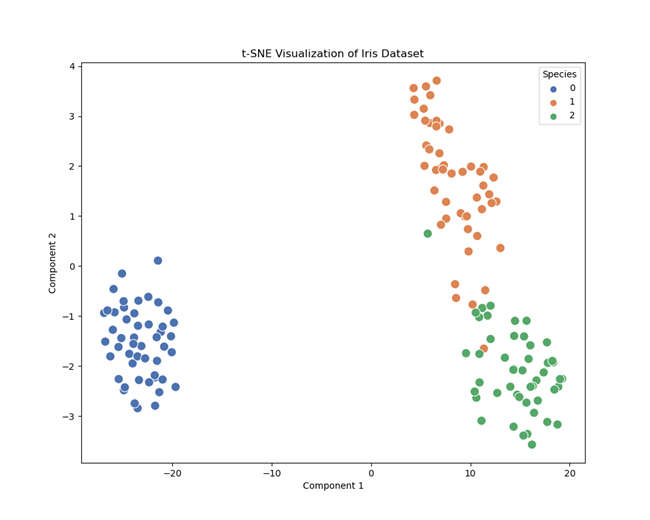
The primary focus of this project is on data visualization, training Support Vector Machine (SVM) models, and building a neural network for classification tasks.
Deploying a CNN model on Kria KV260 edge device and measuring the inference performance.
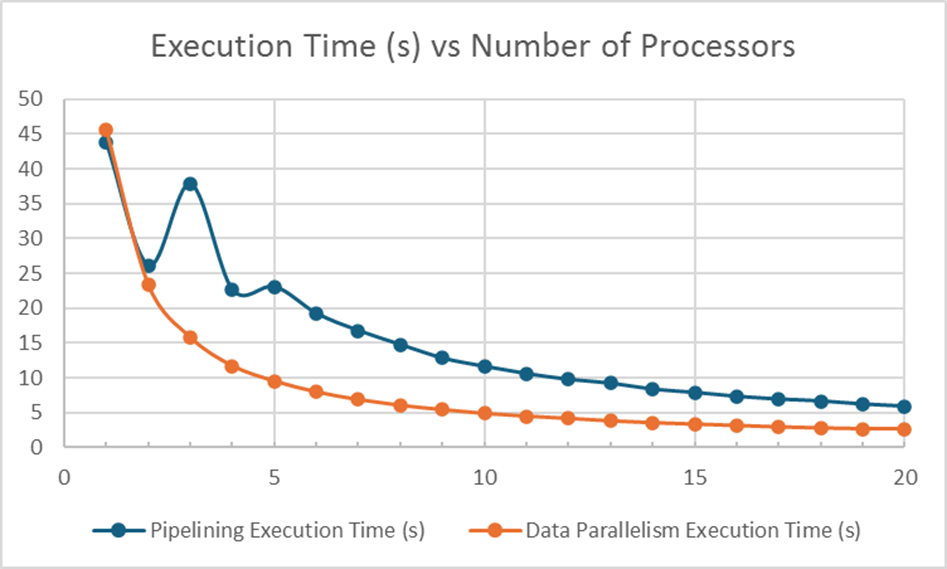
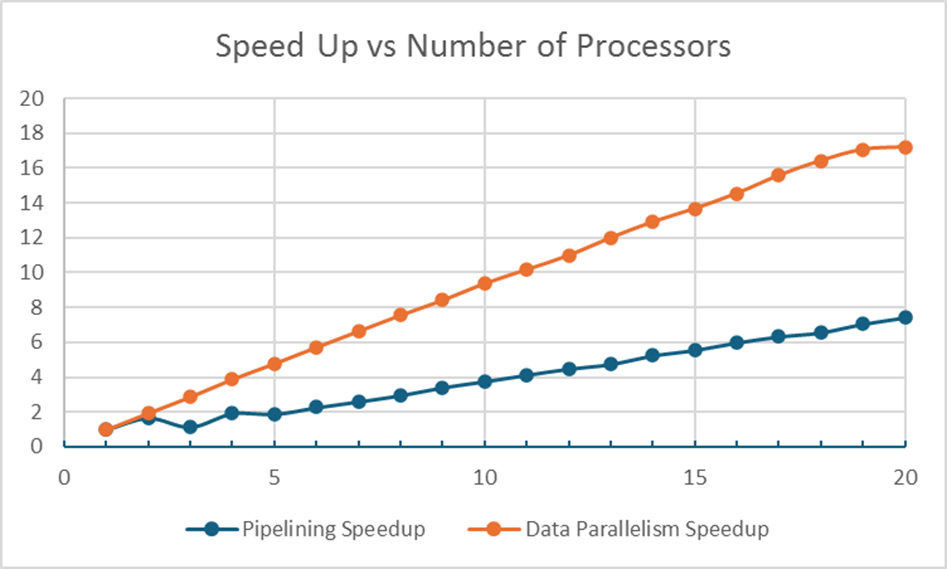
Implemented MPI-based CNN inference with pipelining on CPU clusters for speedup.
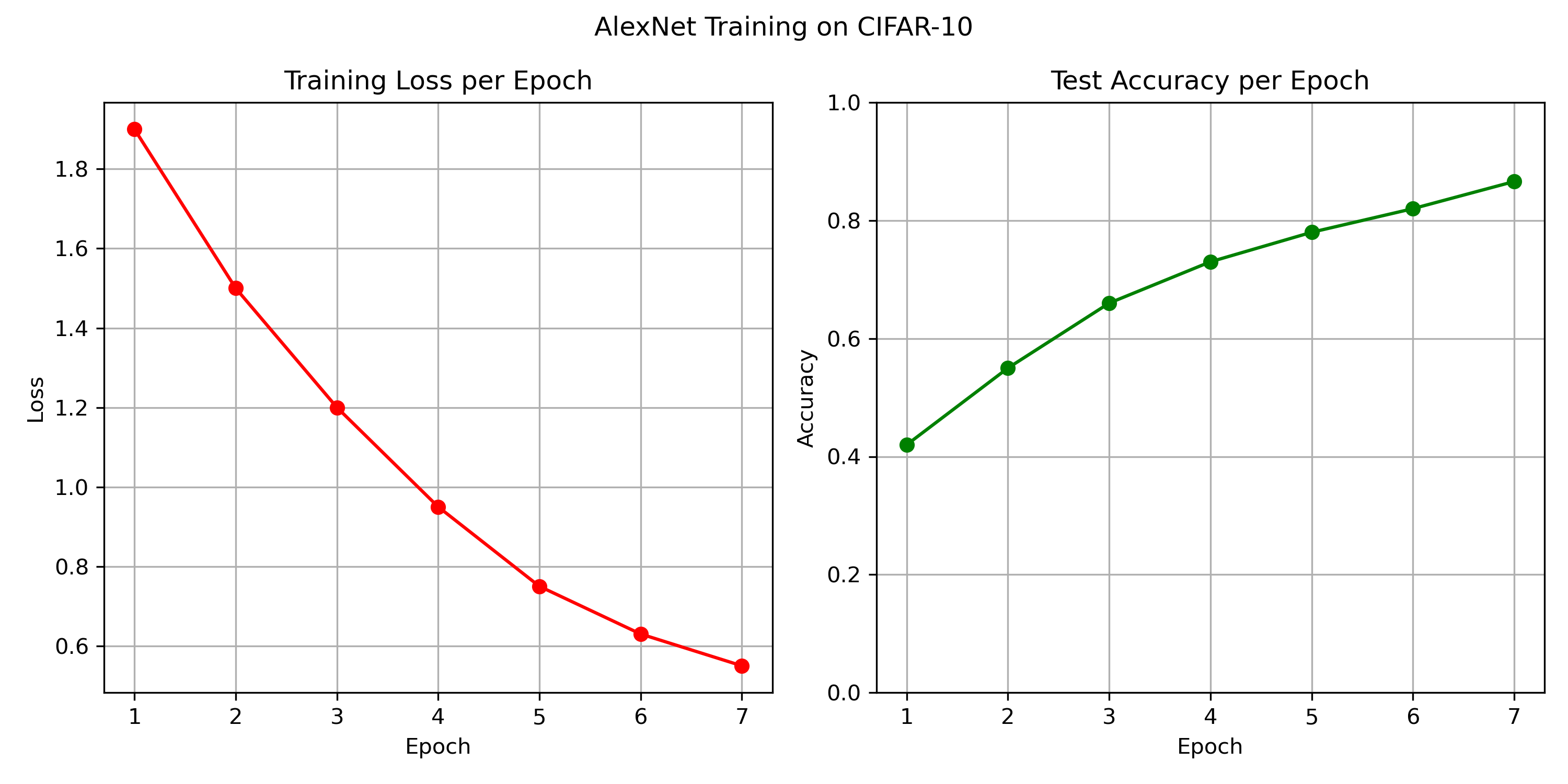
Complete pipeline for training, quantizing, and testing an AlexNet model on CIFAR-10 dataset using PyTorch and Vitis AI.
Designed and developed a C++ engine for performing arithmetic operations on extremely large integers (up to 200 digits), bypassing the limitations of built-in data types.
A desktop application that detects and verifies passenger identities using face recognition and passport data, matching live webcam images with stored passport photos.
Authors: Reza Jahadi, Ehsan Atoofian
Developed a GPU hardware–software co-design to accelerate attention layers by reducing memory footprint and offloading non-MMA operations to tensor cores. Achieved 13.4% performance improvement and 18.3% energy-delay reduction over software-only optimizations.
Authors: Reza Jahadi, Ehsan Atoofian
We propose a value-aware register file design for Tensor Cores that leverages the bit-level sparsity in CNNs to reduce leakage power. By introducing LPS, LPS+, and PLPS+ SRAM cells, we achieve up to 77.3% power savings with negligible accuracy loss.
Authors: Mohammad Hafezan, Reza Jahadi & Ehsan Atoofian
We present PCTC, a co-designed hardware-software approach that enables efficient execution of Capsule Networks on NVIDIA Tensor Cores. By rearchitecting matrix-vector operations and introducing structured pruning tailored to capsule layers, PCTC achieves up to 31% energy savings.
I'm a big fan of movies, especially thriller and mystery genres. I enjoy stories that keep me guessing, with clever plot twists, psychological depth, and suspenseful narratives.
I love traveling and exploring new places. Being in nature whether it's hiking through forests, visiting lakes and waterfalls, or simply enjoying a scenic view that gives me a deep sense of peace and energy. Sometimes you just need to get away from all the noise and chill out in nature to clear your head.